用 TypeScript 实现 SNL 编译器前端
SNL (Small Nested Language) 是我校用于教学的一个非常简单(且不完整)的"高级"编程语言, 编译原理的课设就是实现它的编译器前端部分, 我试着用 TypeScript 完成了这个任务, 整体做下来感觉难度不大,确实是个玩具语言的玩具编译器,这里简单记录一下实现过程。
项目地址: https://github.com/isunjn/snlc
SNL 语言
这是一个长得基本和 Pascal 一样的过程式语言。变量先声明再使用,数据类型支持整型、字符型、数组、记录,过程允许嵌套定义,允许递归调用。作为一个教学用的简易语言,SNL 有非常大的局限性,比如不支持布尔类型和逻辑运算(但比较表达式实际上会产生一个布尔型的值)、条件表达式必须有 else 块且至少一条语句、字符型仅能声明而不能对其赋值……尽管如此,它仍然“具备高级程序设计语言的常见特征”,至少教材上它自己是这么说 :)
一段简单的 SNL 代码:
program p
type
t = integer;
var
t i, j, k;
char ch;
array [1..20] of integer arr;
procdure
fn(integer num);
begin
return(num + 1)
end
begin
read(i);
j := i + k;
fn(j * arr[1])
end.
你还可以看下 sample/ 文件夹下的其他几个代码示例,以及 docs/snl.bnf (注意该文件并没有按照严格的 BNF 格式书写)
词法分析
编译器的第一个组件是词法分析器(lexer),这个阶段会去除掉源代码(字符序列)的注释和空白符,并将各种字符序列转换成为称之为 Token 的表示形式,得到一个 Token List。
DFA
词法分析的主要依据是该语言的词法 DFA,通过 DFA 判断某段字符序列是否合法、如果合法的话具体是哪种词法元素。
SNL 的 DFA:
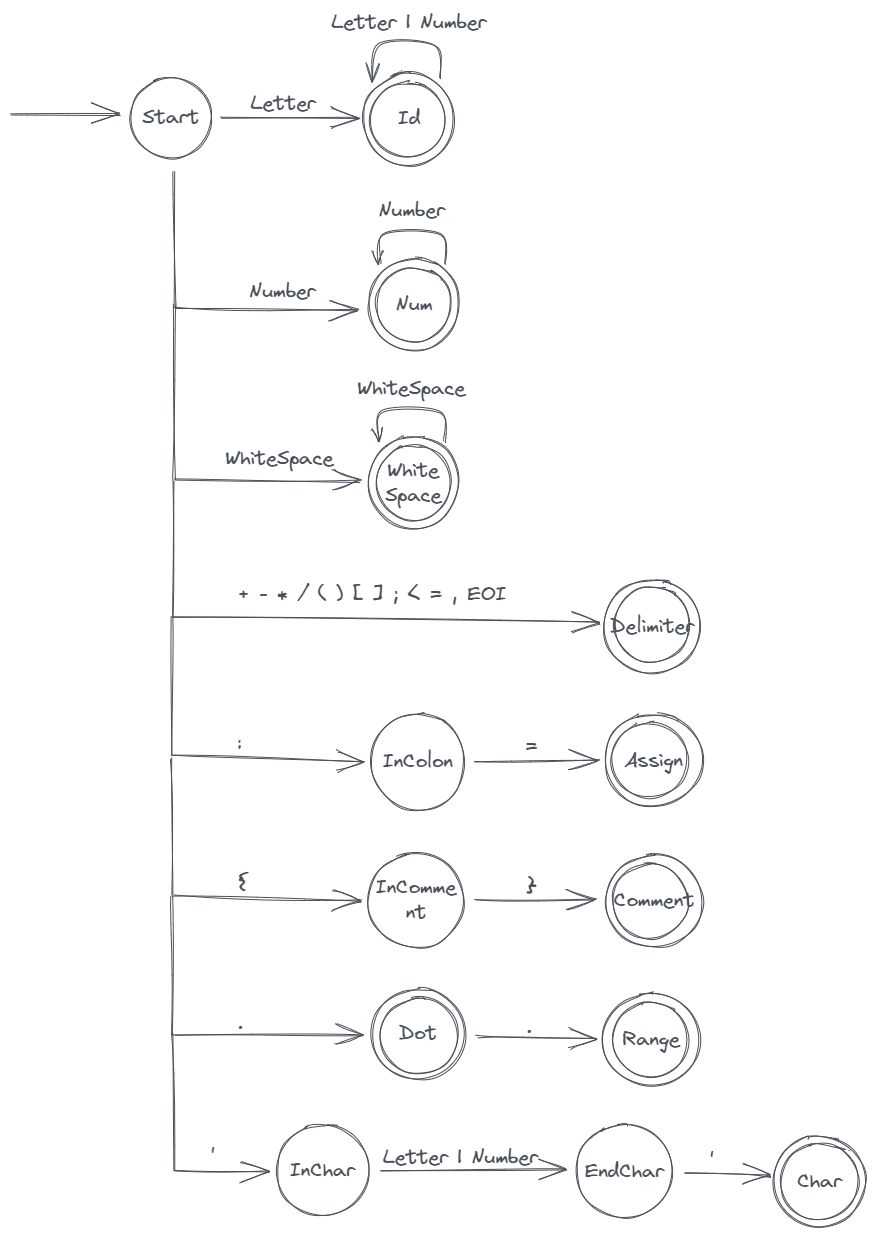
每个状态会根据当前字符进行判断,是转到另一个状态,还是生成一个 Token,还是出错(图中省略了出错状态)。
Token
具体到代码实现,我们需要先定义一下 Token 的数据结构。见 src/common/token.ts,它有四个字段,分别是行号、列号、词法类型(lex)、语义信息(sem)。每个关键字算作一种单独的词法类型,用它的大写表示。并非所有 Token 都有语义信息,标识符、整型、字符型需要记录他们具体的值作为其语义信息,其他 Token 则不需要语义信息部分。
词法分析的实现
见 src/lexer.ts,我们给 DFA 中的每个状态写一个函数,处理该状态内部的情况,这些状态处理函数的参数是当前正在处理的字符和一个将来可能会用作语义信息的字符数组,返回值是另一个状态处理函数(的引用)或者一个 Token 或者一个词法错误。
lexer 函数会对全局变量进行初始化并调用 tokenizer,tokenizer 负责每次完成一个 Token 的解析,返回一个 Token 或一个 LexError。(其实 tokenizer 也是词法分析器的意思,和 lexer 是同义词,不过用在这里表示识别一个 Token 好像也说得过去)
词法分析要考虑的点:
- 字符有时需要“向前看”,当读入下一个字符并判断后可能需要进行回退(goBack),回退时需要考虑好行号和列号的变化
- 注释和空白也作为 Token 返回,但并不加入最终的 Token List
- 标识符判定时需要判断是否是语言关键字
- 根据所处状态进行相应的错误处理(我这里的实现并没有考虑到错误恢复,可能会导致错误连环出现)
语法分析
词法分析完成后,(如果没有词法错误)我们就得到了源程序的 Token List,可以进行下一步的语法分析了。
语法分析根据语言的文法规则对 Token 序列进行解析(parse),生成一颗抽象语法树(Abstract Syntax Tree,AST),或产生语法错误(SyntaxError)。
语言的文法规则是定义好了的,用若干条产生式表示,教材里 SNL 有 104 条产生式,见 docs/snl.bnf。这些规则定义了源码中的 Token 序列能以怎样的方式排列起来(即满足语法要求)。
语法分析分为自顶向下分析和自底向上分析,自顶向下又分为递归向下法和 LL(1) 分析法,因为课设要求自顶向下的这两种方法都要做,所以这里实现了两个 parser。
语法分析的相关原理限于篇幅我在这里就不赘述了,只讲一下具体代码实现。
我们首先定义一下描述文法时需要用到的终结符和非终结符类型,请查看 src/common/grammar.ts,定义文法规则为 Rule,将 104 条规则保存到一个 Map 中,称为 grammar,通过规则的序号来索引。
Predict 集
递归下降法会用到产生式的预测集,当文法中出现一个非终结符有多条产生式的情况时需要根据各产生式的预测集进行下一步动作,LL(1) 分析法也会用到根据预测集构造的预测表。
因为产生式是给定了的,所以实际上预测集也是不变的,可以提前手工计算出来,教材里也是直接给出了(不过教材里的预测集是有错的,话说这教材写得还真是烂呀还真是给了同学们很大的发挥空间)
因为这个玩具项目的主要目的还是学习编译原理,我们实现一遍预测集生成算法也无妨,这里我参考 LL parser - Wikipedia 里关于 LL(1) 分析表的算法描述,实现了预测集和预测表的生成,见 src/common/predict.ts,导出的两个函数分别被两个 parser 使用。
这种预测集 “generated on the fly” 的方式其实是不太合理的,没有必要每次编译都重新进行一遍这样结果已经确定的计算,特别是编译器这种性能敏感型程序。这里主要是出于学习目的。
AST 定义
我们还需要知道语法分析的输出具体是什么,为此我们需要定义抽象语法树的结构,而抽象语法树节点的数据结构定义可能是整个项目最大的难点了。
教材在这里用了一种很奇葩的方式,它将所有不同类型的树节点的字段全部 union 到一个结构体里,再根据类型字段判断哪几个数据字段是有效的……不嫌浪费内存吗.jpg ,正确的做法应该是为每种节点定义一个类型。
SNL 的 AST 有这几种节点:
- 标识符和整形字面量(没有字符型,因为 SNL 实际上并不支持字符型……)
- 根节点,包含程序名、声明部分、程序体部分
- 声明部分,包含类型声明部分、变量声明部分、过程声明部分(过程声明中还包含参数声明部分)
- 语句,分为条件语句、循环语句、赋值语句、写语句、读语句、返回语句
- 表达式,分为操作符表达式、常量表达式、标识符表达式(变量表达式)
- 变量相关节点
节点的具体定义请见 src/common/ast.ts,这里的类型定义使用了 TypeScript 的 type 而不是 JavaScript 的 class,为此需要考虑如何新建节点的问题。因为我们的节点定义里大部分字段的类型并非可为 null 的类型,但后面新建节点时却又需要它暂时为 null,因为在新建时可能还没有字段的具体值,也许应该将其定义为类似 Rust 中的 Option 类型的东西,但这些字段在概念上又确实不为空,所以并不合适,我这里的解决办法是定义了一个 Nullable 泛型,将一个对象类型的所有字段变为可为 null,这样在新建节点时创建目标类型的 Nullable 类型,然后等字段全部赋值后再进行一次类型断言,转为非空类型。
;
通过 createNode 函数来新建一个 NullableNode<T>,根据 kind 参数的值来新建具体的类型。
这样处理确实能用,但感觉不太优雅,代码看起来也比较怪,也许将每一个类型定义为 class 然后写构造函数会更好一点,我的 TS 水平还有待提高 😢
还有我们的语法分析实现并没有考虑错误恢复,每次识别到一个错误就会停止继续解析,局限性很大。
递归下降解析
现在有了 AST 的定义,可以进行具体的语法分析了,先来看看更加直观的递归下降法。
所谓递归下降法,说的是为每一个非终结符写一个子程序,处理其产生式右部,终结符则进行匹配,非终结符则递归调用该非终结符的处理子程序。
很容易可以写出这样的代码:
然后得为每个非终结符都写上一个这样的函数,属于是累活了。
不过仔细观察我们会发现"拿到下一个 Token,判断是否匹配或是否落入预测集,成功则生成相应值,失败则出错"这样的代码逻辑在每一个 parseXXX 函数中都一样,这里的共性暗示着我们可以为其建立一种抽象。
我们通过构建一种函数式风格的、语义化的链式调用来将这种共性抽象出来,它用起来大概是这样:
node.xxx = "XXX""Expect a `xxx`";
这里链式调用的关键是需要为我们的抽象定义一个类,这个类的实例方法会返回类实例本身,因此就可以再次调用另一个实例方法。我们将这个类称为 ParsingWorker,调用 next 函数会返回一个 ParsingWorker 的实例,该实例记录着当前的 Token,然后通过其上的实例方法执行具体的递归下降解析逻辑。
ParsingWorker 上主要有这几个字段:
token- 当前正在处理的 Tokenresult- 每个 Worker 最终都有可能产生一个值(也可能不产生值),用来赋值给某个语法树节点的字段,这个值就是该 Worker 的 resultmiss- 布尔值,当 match 失败或预测集判定失败时置为真
实例方法主要有:
match- 判断当前 Token 是否匹配某个终结符in_predict- 判断当前 Token 是否在某个预测集里then_take- 此方法有一个可选的函数参数,当提供这个函数参数时,就执行它,把其返回值作为最终的 result,如果没有该参数,则根据当前 Token 来产生一个相应的 resultor_err- 若 miss,则 throw 一个语法错误,若没有 miss,则返回 result
具体代码还有更多的逻辑细节,比如它还需要两个泛型参数,用来指定 result 的类型。这里就不展开详细说了,请查看 src/rd-parser.ts
基于 ParsingWorker 我们可以写出这样的 parse 函数:
可以看到代码更加简短,且更加语义化。
更高层级的抽象通常会带来额外的性能开销,这里的 ParsingWorker 跟直接在每个 parse 函数里写 if 相比会有新建实例和方法调用的额外开销,而编译器属于偏底层、性能敏感型的系统级程序,一个真实世界中 non-trivial 的编译器一定不会大量使用有额外开销的抽象。不过咱这是个玩具编译器,为了简洁性和语义化牺牲一点性能完全是可以接受的。
学习 Rust 时接触到一个叫做零开销抽象(zero-cost abstraction)的概念,指的是语言为你提供的抽象相比你自己手写的不会开销更大,相反只会更加高效,"What you don’t use, you don’t pay for. And further: What you do use, you couldn’t hand code any better." 实现这一目标需要语言的精心设计和编译器的优化。Rust 尽力提供零开销抽象,使得在享受抽象带来的便利的同时不会有额外的性能开销,这对于性能敏感型程序是很重要的。
LL(1)解析
LL(1) 解析和递归下降解析的思路是相似的,只不过是把递归的系统调用栈改为自己手动维护的符号栈而已。LL(1) 解析的主要算法请见 src/ll1-parser.ts 中的 parse 函数。
问题在于,我们不仅要对 Token 序列是否合法进行判定,还需要在判定的过程中构建抽象语法树。为此除了符号栈之外,还需要一个语法树栈,以及用于处理表达式的操作数栈和操作符栈。
构建语法树的主要思路是,在将产生式右部压入符号栈时适时地进行一些额外的动作(这里称之为 action),比如创建一个相应的树节点并将其字段指针压入语法树栈,后面再生成节点时会从语法树栈中弹出一个这样的字段指针并将其赋值为该新建的节点,新节点的字段也相应地入栈。
JS/TS 并没有指针类型,你无法取到一个值的“地址”,不过我们可以通过 JS 对象的 可计算属性 来模拟出字段指针的效果。JS 的可计算属性指的是对象的字段可以通过一个在运行时求值的字符串来访问(方括号语法)。语法树栈中的元素是一个二元组,包含一个节点本身的引用和该节点某个字段的字符串表示,这样就可以在后面弹栈后对这个字段进行赋值。
;
;
;
node = value;
这里这个所谓的 Pointer 类型是不能保证类型安全的,需要手动保证字段和节点类型相匹配。
大部分的 action 都是“创建一个新节点,弹出语法树栈的栈顶元素,将其赋值成该新节点,将新节点的相应字段压入语法树栈”,我们将其抽象到一个 link 函数,表示“连接”到语法树。然后观察产生式,为每个产生式定义一个相应的 action(一个函数),大部分 action 都只是调用一次 link。
处理表达式时需要额外的考虑,因为需要处理操作符的优先级问题,所以不能简单地“link”,需要利用操作符栈和操作数栈来构建优先级正确的表达式节点,然后再“link”到语法树上。
观察产生式可以得到这样的结论:
- 在处理 83 号产生式时开始一个表达式的处理
- 在处理 84 号产生式时结束一个表达式的处理,生成本次的表达式节点
观察产生式中有关表达式的其他一些性质,发现还需要 3 个标志变量:
exp_should_link- 表示本次表达式是否需要连接到语法树exp_should_sibling- 表示本次的表达式节点是否有兄弟节点exp_not_over- 表示本次的表达式是否还没有结束
在开始处理表达式时(83 号产生式的 action 处)我们为每个表达式记录一些信息,存在 exp_info_stack 中,这个栈的元素是一个三元组:在操作数栈中的开始位置、是否需要连接、是否有兄弟节点。
然后在和表达式相关的产生式的 action 中对这些标志变量以及操作数栈和操作符栈进行相应的操作就可以正确地构造出优先级正确的表达式节点了,注意在处理表达式时也会暂时性地用到语法树栈。具体的处理逻辑请看代码。
语义分析
完成语法分析后得到了语法树,相应的语法错误也得以检测,下一个步骤是语义分析。由于本项目只完成编译器前端部分,所以语义分析模块只检测语义错误,没有别的输出。
SNL 的语义错误包括:
- 标识符重复定义
- 标识符未声明
- 标识符未非期望的标识符类型
- 数组定义时下界大于上界(教材里很奇怪地把这个错误叫做数组下标越界,但真正的“数组下标越界”应该一个运行时错误,而不是编译时错误)
- 数组索引不是整型,记录类型的域变量引用不合法
- 赋值语句两侧类型不匹配
- 赋值语句左侧不是变量标识符
- 过程调用中形实参类型不匹配
- 过程调用中形实参个数不匹配
- 过程调用处的标识符不是过程标识符
- 表达式运算符两侧分量类型不匹配
- if 和 while 语句的条件部分不是布尔型(但其实这条在语法分析阶段就得以保证了,SNL 的文法保证了条件部分只能是比较表达式)
符号表
语义分析的关键在于构造符号表, 记录程序中出现的所有标识符及它的“种类”信息,分为类型标识符、变量标识符和过程标识符,符号表项称为 TableItem。
类型标识符需要以某种形式记录它的“类型”,变量标识符也需要,另外还需要记录变量是按值访问还是按引用访问,过程标识符则需要记录参数的信息,一个参数可以当作一个变量标识符来对待。
“类型”信息使用 Ty 来表示,整形、字符型、布尔型属于原始类型,只需要单独的一个实例就可以,array 和 record 类型则每个类型都不同,需要记录自己的额外信息,array 需要记录它的元素的“类型”,record 需要记录它的域的相关信息。
TableItem 和 Ty 的具体定义请见 src/sem-analyzer.ts,当处理程序时,每个作用域会有一个符号表,整个程序有一个 Ty 表(一个数组)来记录所有出现的“类型”。
语义分析在分析程序的声明部分时建立符号表,在分析程序的语句部分时遇到标识符则查找符号表,在这个过程中进行类型检查和其他语义错误检测。
作用域
语义分析的一个关键在于“作用域”的处理,SNL 支持嵌套过程定义,每个过程内部都算作一个新的作用域,在这个作用域里可能会存在作用域遮蔽效应,即本地标识符定义覆盖了外部作用域中的标识符定义。
每个作用域都有一个符号表,这些符号表组织在一个栈中。
代码实现上语义分析分为 build 和 check 两个主要动作,在声明部分(主程序的和每个过程的)进行构建/维护符号表(build),在语句部分进行相应的语义检查(check),遇到过程定义时递归地向下处理,这时会新建一个作用域(nest in),处理完一个过程后销毁该作用域(nest out)
check 可以分为语句检查、表达式检查和变量检查,在 check 阶段只需要针对上面列出的语义错误在相应的位置写具体的逻辑就好。具体逻辑请看代码,注意代码里的 Scope 类表示整个作用域集合,而不是单独的一层作用域。
到这里,这个玩具编译器(前端)就基本完成了。
命令行界面
再来做一下命令行界面,命令称为 snlc (SNL Compiler),第一个参数是需要编译的 snl 文件路径,另外有这些标志参数:
--set打印预测集--table打印预测表--token打印 Token 列表--ast打印抽象语法树--ll使用 LL(1) parser,默认是递归下降 parser
Pretty Print
还可以让命令行输出更加“用户友好”一些。
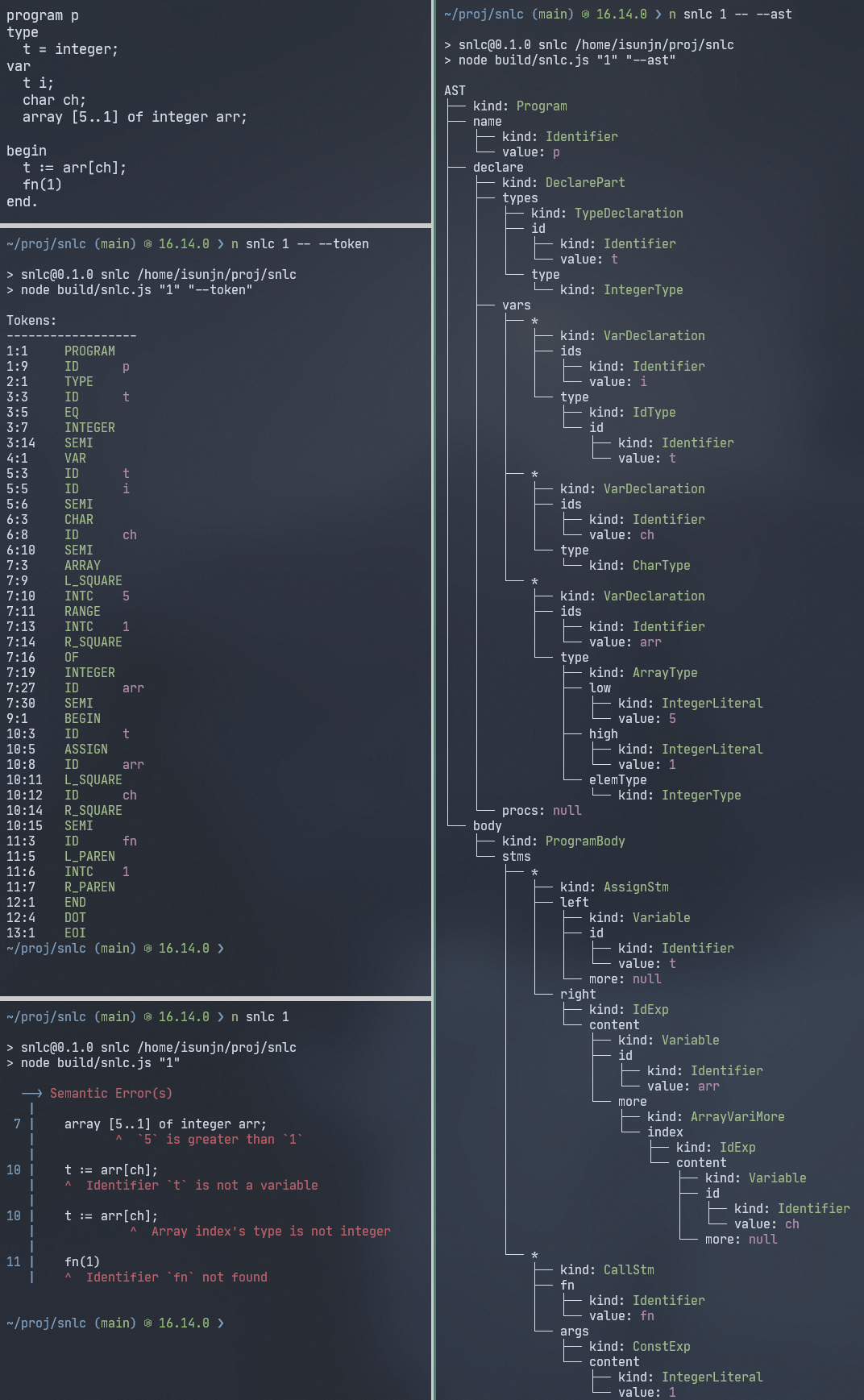
打印错误信息时模仿了 Rust 编译器的错误输出风格,会显示行号和那一行的代码,指出错误的位置。
打印 AST 时则使用了 Linux 的 tree 命名风格的树形输出,这个效果的实现关键在于递归打印时维护一个 prefix 栈。
总结
总的来说,这确实是一个大学生课设级别的玩具语言的玩具编译器实现,还只有前端部分,但真正动手实现一个编译器仍然让我学到了很多东西,也让我体会到了编译器的奥妙。等之后有时间了想再系统地学一学相关的知识,看一下那本编译原理龙书,还有那本《Crafting Interpreters》,可能要等到秋招之后了。